搜索
登录

分享

复制
Deepseek V4发布,电商怎么借力呢?
成长猫跨境
出海网跨境电商
关注:公众号
2026-05-06 15:31:52

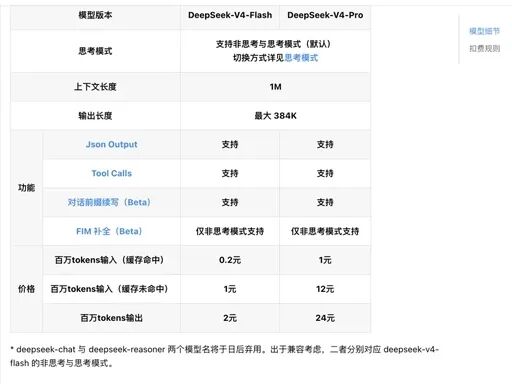
DeepSeek V4正式发布,对电商卖家意味着“低成本AI员工”时代到来。该模型基于华为昇腾国产芯片,支持百万级Token长上下文,彻底解决“记不住长文档”的痛点。配合Agent智能体,它能自动处理选品、文案、客服等全链路任务,且成本仅为海外模型的十分之一(百万Token输出低至2元),让中小卖家也能用得起顶级AI算力。
最新的 AI 发展情况,国产大模型 DeepSeek V4 终于发布了。这在AI圈可是一件大事。

01、最近Deepseek最近半年情况
2025 年上半年的时候,DeepSeek 突然火起一阵,但是大家回忆一下,下半年基本上一直没啥动静,就突然没什么声音了。就是我们一度都以为这个DeepSeek 是不是已经过气了。
你像我们自己公司,遇到决策型的问题(如下个月目标怎么定、核心做哪三个方向、OKR怎么拆分),就让 Gemini 帮我们决策;我们需要那种工作型(如P图、写文案),我们用 GPT;如果生活里面的一些小事(手机不知道怎么设置、减脂健康饮食吃什么),让豆包这边帮我弄一下。
所以工作和生活分别用不同的模型,那个 DeepSeek 在最近半年可能没有什么存在感哈。但是突然出来这个 V4.这个对大家(特别是咱们电商卖家)来说有什么意义啊?
02、龙虾和大模型能干啥
咱们毕竟不是那些搞编程的,咱们是一帮做电商的。以前咱们跟 AI 这边就只能聊天,它叫聊天机器人。像那个豆包,它很会提供情绪价值,天天哄着你玩,你问它问题,它给你回答。
但是毕竟咱们做电商是要挣钱的。从 26 年回来之后,大家突然发现有个叫“龙虾”的东西突然火起来。龙虾它是一个 Agent,就是它是帮你干活的。你说去帮我P个图、剪个视频、在群里发个消息、把员工周报统计一下,它都能干。
但是龙虾它只会去干,它没脑子。脑子就是各家的大模型(比如国内的千问、豆包、DeepSeek,国外的Gemini等)。你把大模型套到你这个 Agent 里面,它就有脑子了,就能干活了。所以大模型负责想,Agent负责干。
03、为什么不直接用国外的?
以前如果你想用 DeepSeek,不是特别好用,因为如果你把公司的知识库几十万字全丢给它处理问题,它处理上下文的能力比较差。国外的能做 100万 Token 的量,那直接用国外的行吗?问题有两个:
不给你用:
不是交了钱就给你用,动不动还封你号。
死贵:
美国的高收费,认为AI强就应该贵。比如开个 Claude Code 一个月要 200 美金。如果想自动化编程,更贵。Token、API、算力都要钱。所以过去老板画饼说用AI取代员工,实际上AI干活一个月的成本都得大几千,比员工还贵。
所以咱们作为使用者角度来说,肯定是主动权在自己手里更好,越便宜越好,最好就是国产的大模型,便宜实惠,差不多够用就行。
04、为什么DeepSeek V4特别有意义
原本全球国外的 AI 行业对我们其实是有两把锁的,我们相当于是被装在一个铁笼子里面。
第一把锁:英伟达的芯片和 CUDA 的生态
咱们国内不是没有人会做AI的应用,像豆包、千问其实做的挺好。但是底层的路是人家修的,无论训练还是推理的过程中,全都被英伟达的 GPU 和 CUDA 的生态里面给锁死了。
自研生态突破: DeepSeek V4 这次最狠的地方是在于,它是跑在华为的昇腾芯片上,完全国产的。这不是简单地把英伟达的芯片拔下来插上华为的芯片。因为英伟达厉害不只是芯片卡,还有CUDA的生态(相当于AI世界的操作系统),过去的AI研发都是基于这个架构。现在DeepSeek V4用了华为昇腾芯片加上CANN 架构,所有的代码全都得重新写。就相当于华为自研芯片做手机,还得搞鸿蒙系统重新适配一样,这是非常难的,但是非常有意义。

我们怕的不是产品做出来比别人,而是在于整个生态上,人家告诉你说最核心的技术必须外国才能做(就像以前汽车三大件、手机芯片只能组装)。
我们现在要做的不是必须做到最好,而是只要我们能自己做,就已经突破了第一步,突破封锁了!
第二把锁:长上下文与算力
以前的大模型特别能说,但是它脑子比较差,记不住事情。你给它一个字非常多的文档,它根本没认真看就开始胡说乱讲,这就是大家说的AI有幻觉。
现在DeepSeek V4 支持单次对话 100万的 Token 上下文,就意味着它终于可以完整地把你的信息看完,不会只看一部分就给你胡诌。
现在AI不是只拿来聊天了,直接拿DeepSeek V4 模型套进 Agent 里,它就能完整地给你处理任务。以前像个失忆的员工,现在 DeepSeek V4的性能已经接近 Claude Opus 4.7!而且价格很低:百万 Token 输出 Flash 版本是 2 块钱(海外同类型AI 几十块),Pro 版本是 24 块钱(海外同类型AI 100多块)。
05、总结一下
目前 DeepSeek V4 发布之后,对咱们做电商的帮助:
打破了AI必须花很多钱的局面:以前花几百几千舍不得测,现在用着便宜很多。电商老板最在意的就是成本和利润问题。
更好用了:算力更猛了,大模型配合Agent能真正帮你干活了。
DeepSeek V4 还是猛的,两把锁,锁不死,卡不住。越封锁,我就越自己造,路堵死,我就自己开一条路!牛!
【版权提示】信息来自于互联网,不代表出海网官方立场,内容仅供网友参考学习。如发现本站内容存在版权问题,烦请提供版权疑问、身份证明、版权证明、联系方式等发邮件至 jechynwu@chwang.com ,我们将及时沟通与处理。如若转载请联系原出处










免费下载


企业跨境出海综合服务平台



新手指南
热门推荐
平台常见问题
版权归出海网跨境电商(广州)有限公司所有 粤ICP备2021037671号-5